From Prompt Engineering to Prompt Science
Production LLM prompts have dozens of implicit dials — formality, brevity, empathy, assertiveness, technical depth — and each response is judged on dozens of quality metrics. Teams currently tune these by hand, one A/B at a time, with no way to see how the dials trade off against each other. globalMOO replaces that workflow with a learned surrogate model that solves the inverse problem: given the response qualities you want, find the persona parameters that produce them.
Real-World Impact
What used to be weeks of manual A/B testing — with no guarantee of finding a globally good configuration — collapses to a single optimization run that simultaneously hits every quality target without the trade-offs inherent in one-variable-at-a-time tuning.
The LLM as a Black-Box Twin
The calibrator wraps any LLM in the same twin abstraction globalMOO uses for chemical reactors and solar plants: parameter vectors go in, measurable outputs come out. globalMOO learns the mapping — including the messy, nonlinear interactions that make manual prompt tuning so frustrating — and then inverts it to recommend the exact persona configuration for your goals.
Input Variables (6–20)
Continuous persona parameters: formality, brevity, assertiveness, empathy, technical depth, urgency, friendliness, structure, and any other prompt dimension you can describe. Each parameter has natural-language anchors at calibration points along its range.
Objectives (up to 50)
Self-reported scores extracted from the LLM’s JSON response (confidence, word count, sentiment) plus rubric-graded quality metrics scored by a separate grader LLM (tone, clarity, safety, helpfulness, factual accuracy).
Two-Phase Workflow
- Training — the calibrator runs a Latin Hypercube design across the parameter space, evaluates each design point through the live LLM and grader, and hands the resulting input–output pairs to globalMOO to build a surrogate model.
- Optimization — globalMOO solves the inverse problem against your objectives. Each iteration proposes a new persona configuration, the calibrator scores it against your test cases, and the loop closes until every objective is satisfied.
- Inspection — every API call, system prompt, grader response, and score is logged for full reproducibility and audit.
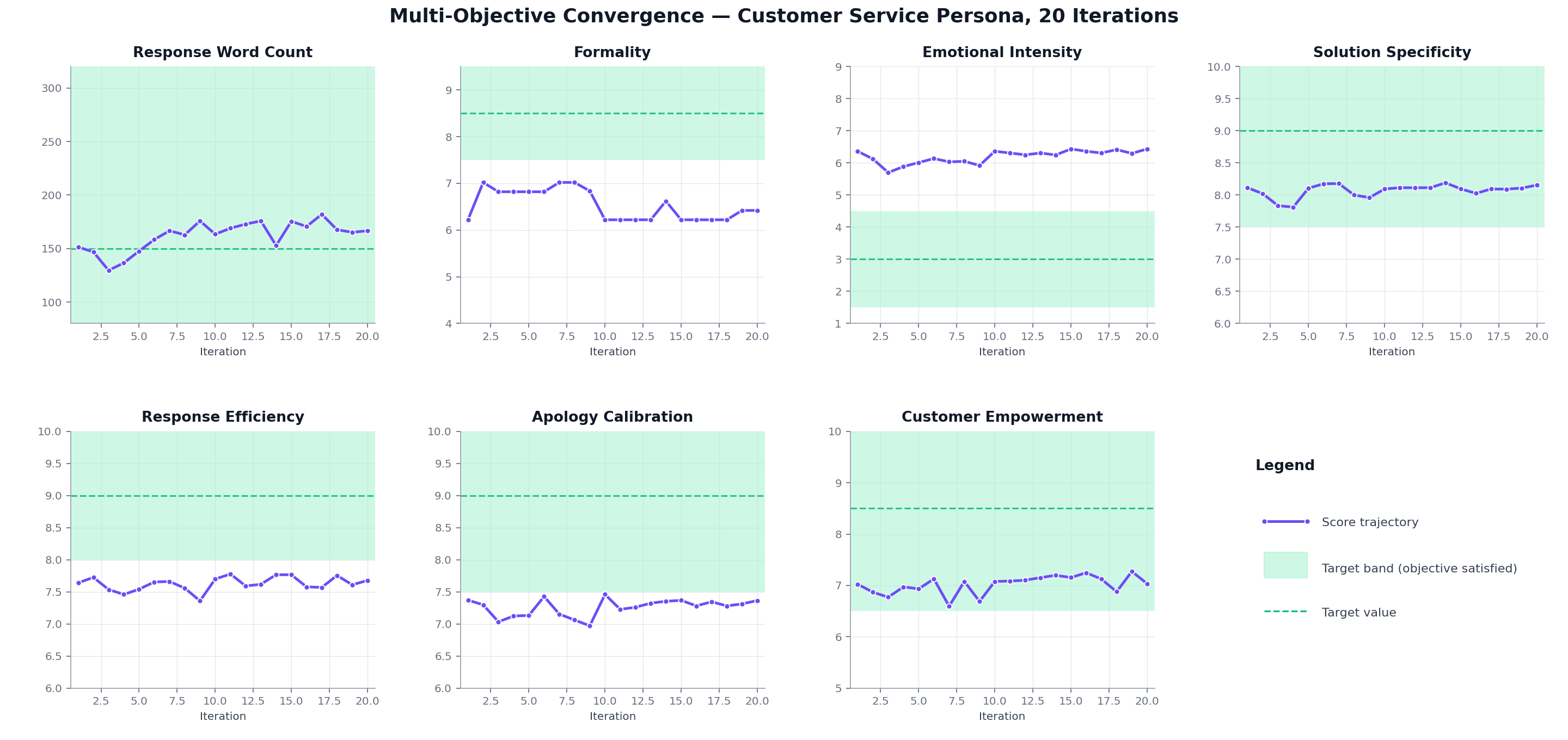
All Objectives Optimized in Parallel
Real telemetry from a 20-iteration calibration run of a customer-service persona under deliberately aggressive target bands. The optimizer moves all seven quality dimensions in parallel — response length, formality, emotional intensity, solution specificity, response efficiency, apology calibration, and customer empowerment — instead of optimizing one at a time and praying nothing regresses.
globalMOO vs. Manual Prompt Engineering
Manual prompt engineering optimizes one trait at a time and hopes the others don’t regress. globalMOO orchestrates every persona dial simultaneously while monitoring every quality metric in parallel.
- Inverse problem solving — specify the response qualities you want; the platform returns the parameter values that produce them.
- Trade-off visibility — quantify the cost of pushing one objective harder, instead of discovering it in production.
- Test-case coverage — every configuration is scored against a battery of representative prompts, not just a single example.
- Reproducibility — every run is versioned, logged, and replayable. Surrogate models can be reused for new objectives without retraining.
Built-In Problem Library
The Persona Calibrator ships with six fully-specified problems covering the most common production prompt patterns — ready to run, modify, or use as templates for your own:
Email Writer
Professional email drafting calibrated for tone, structure, and length across recipient contexts.
Customer Service
Support agent persona balancing empathy, resolution speed, and policy compliance.
Marketing Copy
20-input, 50-output content generator tuned for brand voice and conversion-oriented metrics.
Medical Triage
Clinical decision support calibrated for accuracy, caution, and escalation behavior.
AI Content Moderator
Moderation policy tuned for precision, recall, and explanation quality.
AI Workflow Reviewer
Safety review agent calibrated to surface risks without false positives.
Calibration Economics
A full optimization run costs less than lunch — without sacrificing rigor. Built-in Anthropic Batch API support, prompt caching, and Haiku-class graders keep the per-run bill under a few dollars even for 50-objective problems.
Workbench: Calibrate Without Writing Code
A browser-based workbench wraps the entire workflow — problem authoring, prompt preview, evaluation, training, optimization, and run inspection — behind a guided UI. Every screen exposes the same primitives the CLI uses, so analysts and engineers work from the same source of truth.
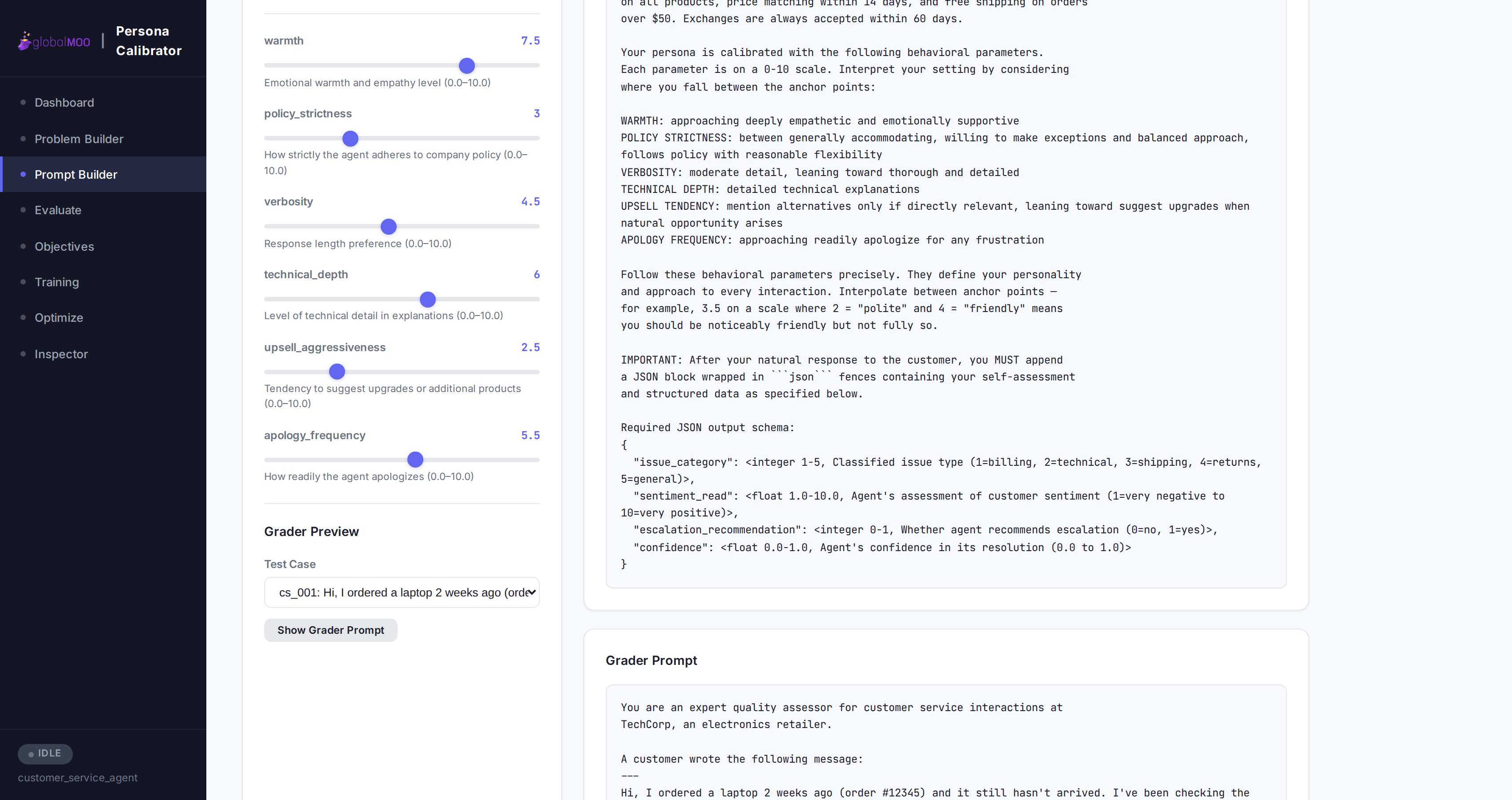
Author Prompts with Live Preview
Drag the parameter sliders and watch the system prompt regenerate in real time — including natural-language interpolation between calibration anchors, so the model sees prose like “between professional-friendly and formal” rather than raw numbers.
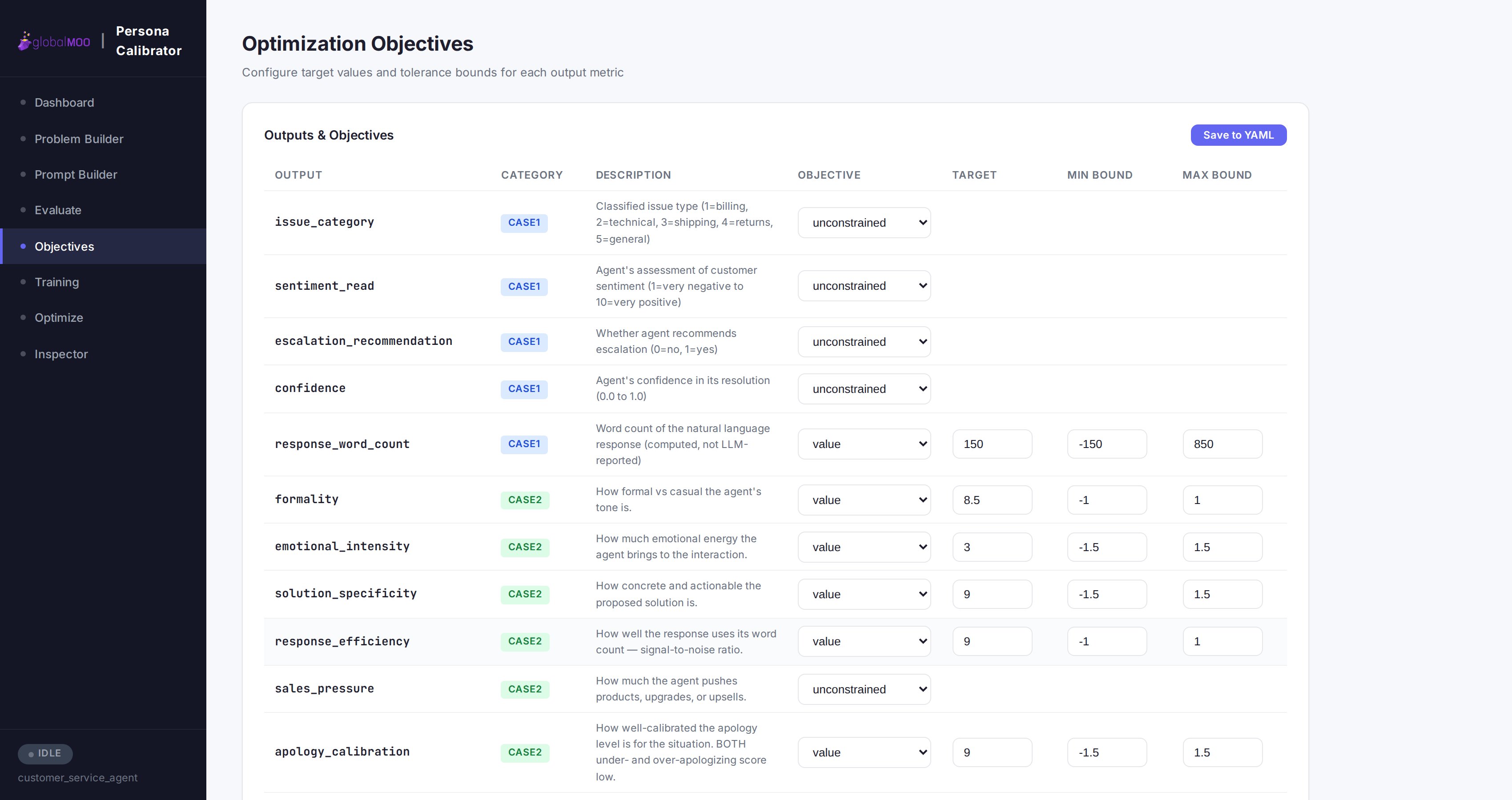
Configure Every Objective Independently
Each output metric can be targeted, minimized, maximized, or left unconstrained, with explicit tolerance bounds. Configuration is saved back to YAML with comments and formatting preserved — never a lossy round-trip.
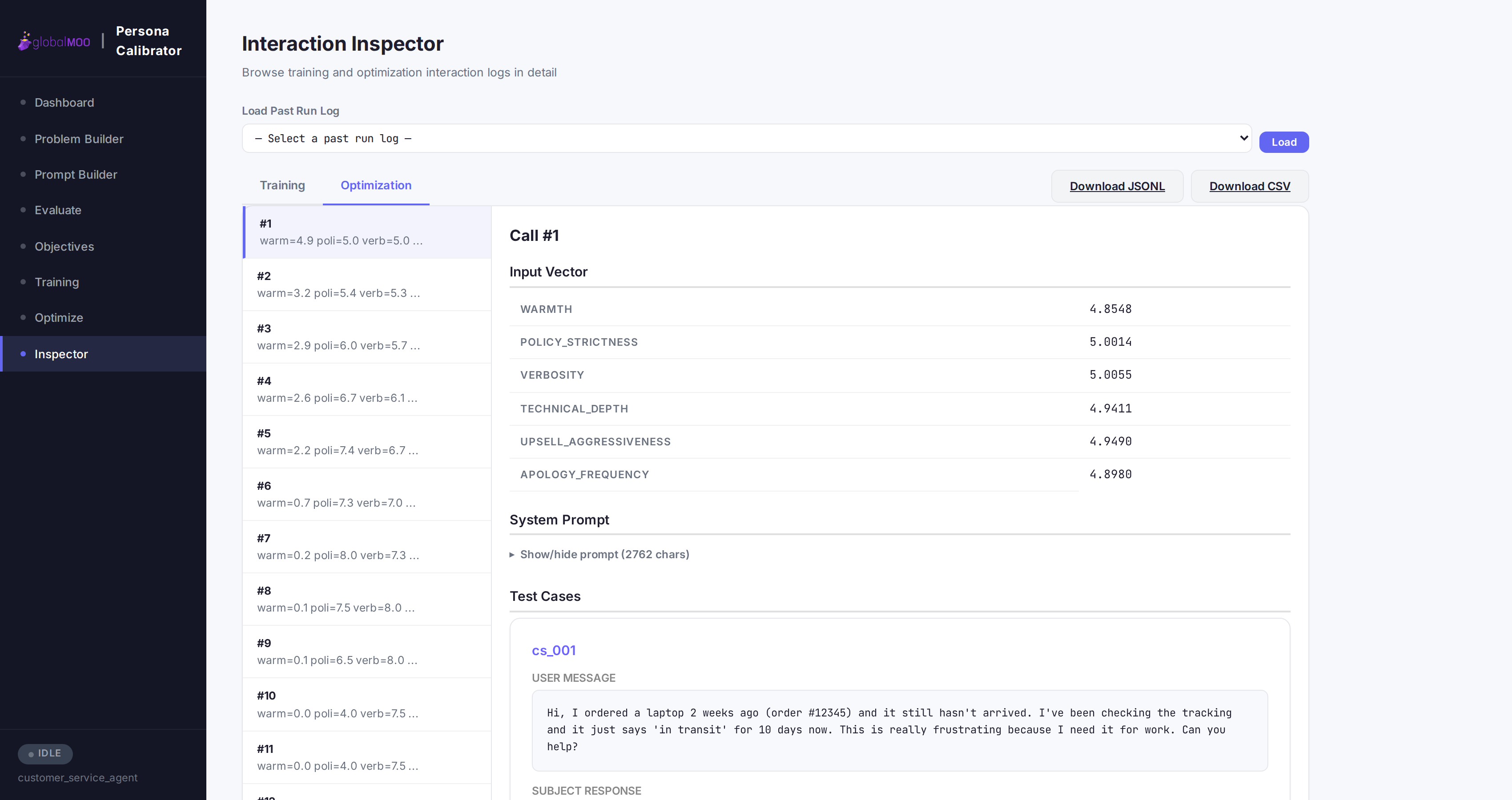
Every Call Logged and Auditable
The Inspector lets you replay any past run iteration by iteration: the exact system prompt, the LLM’s raw response, the extracted output values, the grader’s reasoning, and the resulting scores. Reproducibility is not a bolt-on — it’s the default.